Retrieval failure or generation failure? ContextLens tells you which one.
A wrong answer from your RAG system either means the right document was never retrieved
— or it was retrieved and the AI misrepresented it. These need completely different fixes.
No other tool makes this distinction.
You've built a RAG system. Sometimes the LLM gives a wrong answer. You open
your observability tool and see: faithfulness: 0.6.
Now what?
That number tells you something went wrong. It doesn't tell you whether
the right document was never fetched — in which case you fix your search —
or whether it was fetched and the AI ignored what it said — in which case
you fix your prompt. Those are completely different problems.
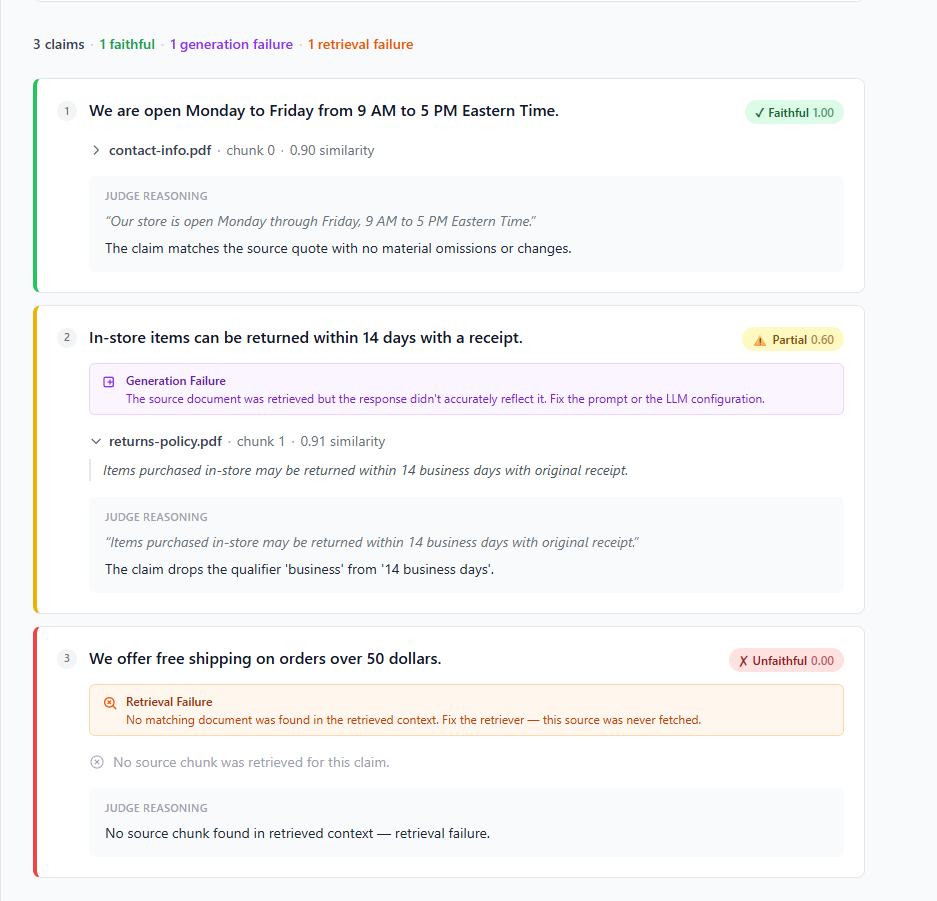
Current tools measure. ContextLens diagnoses. Every flagged claim
comes with a category: retrieval failure or generation failure.
You always know which problem you have before you touch anything.
Retrieval Failure
The right document was never fetched.
The retriever returned wrong or irrelevant chunks. The LLM had
no source to work from and generated from training data instead.
Fix the search, chunking, or embedding strategy.
— vs —
Generation Failure
The right document was there. The AI misrepresented it.
The correct chunk was retrieved. The LLM dropped a qualifier,
changed a number, or softened language. A subtle misrepresentation
that can be caught claim by claim.
Fix the prompt or model configuration.
How It Works
Four steps. One clear answer.
1
Decompose
Every LLM response is broken into atomic, self-contained claims.
A response with three facts becomes three independently verifiable statements.
2
Attribute
Each claim is compared via vector similarity to every retrieved
chunk. The closest matching chunk is linked — or the claim is flagged
as having no source.
3
Score
For attributed claims, an LLM judge checks whether the AI accurately
represented the source. It catches dropped qualifiers, changed numbers,
softened certainty — with a plain-English explanation.
4
Surface
Every claim shows you exactly which failure you have: the document
was never found (fix search) or it was found and misrepresented
(fix the prompt). Never a single conflated score.
The Distinction
From a number to a decision.
Other tools give you
faithfulness:0.6
Something is wrong. You don't know what. You don't know whether to
improve your retriever or rewrite your prompt. You guess, make a
change, and wait to see if the number moves.
ContextLens tells you
Claim 3 has no source chunk.
● Retrieval Failure
Fix the search. That document was never fetched for this query type.
Claims 1–2 were retrieved correctly. The AI dropped
"business" from "7 business days."
● Generation Failure
Fix the prompt. The source was there. The model misrepresented it.
Built and validated against a real RAG app — not synthetic benchmarks.
The attribution threshold was initially calibrated on near-verbatim test data. When run
against an actual policy-document RAG system, correctly sourced claims were being
miscategorized as retrieval failures because real LLM paraphrases score differently than
verbatim extractions. The fix — a three-band confidence model — came from specific
evidence from specific traces, not guesswork. Every calibration decision is documented
in the build log with the exact claim texts and similarity scores that drove it.